转载: https://www.anquanke.com/post/id/240105
0x00 前言 这篇文章主要从源码角度剖析AFL的编译时插桩(compile-time instrumentation)。AFL超级棒的一点在于其“灰盒”的特性:通过编译时插桩获动态获取目标程序的边覆盖信息。此外,AFL的forkserver机制使得AFL在运行过程中只需调用一次execv()函数,避免了多次调用execv()引起的开销(注:每执行一次execv(),都需要将目标程序加载到内存,进行链接等操作)。
注意:本文只分析能获得目标程序源码、开启forkserver下的AFL的一些内部实现,主要以afl-gcc为例对插桩代码进行解读,涉及到的源文件主要有afl-fuzz.c,afl-as.c,afl-as.h 和 afl-gcc.c。
0x01 插桩 AFL的插桩在汇编阶段实现。在获取目标程序源码后,首先需要通过afl-gcc/alf-g++ 编译目标程序,对目标程序进行插桩,得到插桩后的二进制文件。而从源文件到可执行文件,需要依次经过:预处理 、编译、汇编、链接。其中,编译器将预处理后源文件编译成汇编代码,汇编器将汇编代码翻译成机器语言,而AFL的插桩就是在汇编阶段实现。
afl-gcc本质上是一个gcc的wrapper,afl-gcc通过gcc 的-B 选项设置编译器的搜索路径为afl_path/as 。我们编译好AFL后,会在afl的根目录下生成afl-gcc、as 和 afl-as 等文件,其中,as作为符号链接指向afl-as 。接下来,本文将着重分析 afl-as.h 和 afl-as.c文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 /* afl-gcc.c */ u8 *afl_path = getenv("AFL_PATH"); if (afl_path) { tmp = alloc_printf("%s/as", afl_path); //tmp = afl_path/as if (!access(tmp, X_OK)) { //判断对tmp是否有执行权限 as_path = afl_path; ck_free(tmp); return; } ck_free(tmp); } cc_params[cc_par_cnt++] = "-B"; cc_params[cc_par_cnt++] = as_path; ...
afl-as.c首先通过函数add_instrumentation() 在汇编层面对目标程序进行插桩,然后再调用gcc默认的汇编器as 或者用户设置的汇编器执行真正的汇编过程(注:用户可以通过设置环境变量AFL_AS自定义汇编器 )。
1 2 3 4 5 6 7 8 9 10 11 12 /* afl-as.c */ int main(int argc, char** argv) { ... if (!just_version) add_instrumentation(); if (!(pid = fork())) { execvp(as_params[0], (char**)as_params); //真正的汇编过程,as_params[0] = afl_as ? afl_as : (u8*)"as"; FATAL("Oops, failed to execute '%s' - check your PATH", as_params[0]); } ... }
add_instrumentation() 插桩的大致思路:首先,只对.text段进行插桩,afl-as通过字符串疲惫判断是不是.text段;其次,遍历目标程序对应的汇编文件的每一行代码,然后判断其是不是一个基本块的开始,如果是的话,就在这行代码之前进行插桩。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 /* afl-as.c */ while (fgets(line, MAX_LINE, inf)) { .... if (!strncmp(line + 2, "text\n", 5) || !strncmp(line + 2, "section\t.text", 13) || !strncmp(line + 2, "section\t__TEXT,__text", 21) || !strncmp(line + 2, "section __TEXT,__text", 21)) { instr_ok = 1; continue; } .... if (line[0] == '\t') { if (line[1] == 'j' && line[2] != 'm' && R(100) < inst_ratio) { fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); //插桩 ins_lines++; } continue; } ... }
先看一下fprintf函数的原型,注意到第二个参数是格式化字符串,从第三个参数开始都将作为格式化字符串的参数,fprintf会将最终的输出输出到stream所指向的流中。
1 int fprintf(FILE *stream, const char *format, ...);
插桩的语句是fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)) ,通过这行代码,afl-as可以将桩代码插入目标程序的汇编文件。outf是一个指针,指向被插桩的汇编文件;trampoline_fmt_*是要插入的桩代码;R(MAP_SIZE)是0~MAP_SIZE之间的一个随机数,作为trampoline_fmt_*的参数,其实质是为当前基本块分配的ID。
接下来,以32位为例,分析插的桩代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 /* afl-as.h */ static const u8* trampoline_fmt_32 = "\n" "/* --- AFL TRAMPOLINE (32-BIT) --- */\n" "\n" ".align 4\n" "\n" "leal -16(%%esp), %%esp\n" "movl %%edi, 0(%%esp)\n" "movl %%edx, 4(%%esp)\n" "movl %%ecx, 8(%%esp)\n" "movl %%eax, 12(%%esp)\n" "movl $0x%08x, %%ecx\n" "call __afl_maybe_log\n" "movl 12(%%esp), %%eax\n" "movl 8(%%esp), %%ecx\n" "movl 4(%%esp), %%edx\n" "movl 0(%%esp), %%edi\n" "leal 16(%%esp), %%esp\n" "\n" "/* --- END --- */\n" "\n";
这段的代码的主要作用是:
将edi等寄存器保存到栈上。第8-12行代码将寄存器edi、edx、ecx、eax保存到栈上。
将寄存器ecx的值设置为fprintf()中传入的R(MAP_SIZE),第13行中%08x对应的值是R(MAP_SIZE),R(MAP_SIZE)的作用是生成一个0~MAP_SIZE间的随机数。
调用__afl_maybe_log。
恢复edi等寄存器,对应于代码的15行到第19行。
接下来看__alf_maybe_log
1 2 3 4 5 6 7 8 9 10 11 "__afl_maybe_log:\n" "\n" " lahf\n" " seto %al\n" "\n" " /* Check if SHM region is already mapped. */\n" "\n" " movl __afl_area_ptr, %edx\n" ;__afl_area_ptr指向共享内存 " testl %edx, %edx\n" " je __afl_setup\n" "\n"
在__afl_maybe_log里面,会首先判断共享内存是否映射完成(我觉得这里也是在判断forkserver进程是否启动;__afl_area_ptr指向共享内存,在后面会解释),如果未完成映射,会执行__afl_setup;如果映射完成,那么会执行 __afl_store。
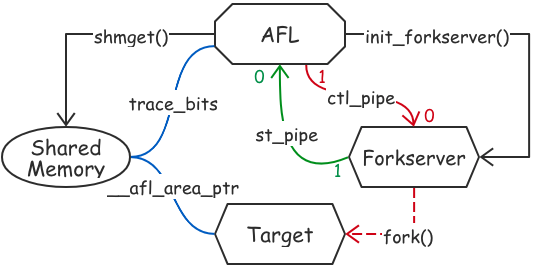
0x02 共享内存 共享内存主要用于AFL进程和target进程通信。target进程可以通过写入共享内存更新target的覆盖信息;而AFL进程可以在target执行完毕后,通过访问共享内存获取target的覆盖信息。
”共享内存“是Linux下进程间的一种通信方式,两个进程将各自的一段虚拟内存空间映射到同一块物理地址上,然后这两个进程就可以通过操作这块物理地址进行通信。Linux下共享内存的具体实现方式: int shmget(key_t key, size_t size, int shmflg);。但是创建完共享内存时,它还不能被任何进程访问void *shmat(int shmid, const void *shmaddr, int shmflg);。
AFL进程中共享内存设置 AFL通过共享内存获取一个测试用例对目标程序的边覆盖信息。AFL开启后,会通过setup_shm()设置共享内存。shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600); shm_str = alloc_printf("%d", shm_id); setenv(SHM_ENV_VAR, shm_str, 1);trace_bits attach到共享内存:trace_bits = shmat(shm_id, NULL, 0);,然后AFL就可以通过trace_bits访问共享内存。在每次执行target之前,AFL会将trace_bits 清零。
target进程共享内存设置 在__alf_maybe_log 中,如果共享内存未完成映射,就会执行je __afl_setup设置共享内存。__afl_setup的作用是获取AFL进程设置的共享内存标识符,并在target进程内attach上去。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 "__afl_setup:\n" "\n" " /* Do not retry setup if we had previous failures. */\n" "\n" " cmpb $0, __afl_setup_failure\n" " jne __afl_return\n" "\n" " /* Map SHM, jumping to __afl_setup_abort if something goes wrong.\n" " We do not save FPU/MMX/SSE registers here, but hopefully, nobody\n" " will notice this early in the game. */\n" "\n" " pushl %eax\n" ;将eax寄存器压栈 " pushl %ecx\n" ;将ecx寄存器压栈 "\n" " pushl $.AFL_SHM_ENV\n" ;压入getenv的参数 " call getenv\n" ;getenv(AFL_SHM_ENV),返回值存储在eax寄存器 " addl $4, %esp\n" "\n" " testl %eax, %eax\n" ;判断环境变量AFL_SHM_ENV是否存在 " je __afl_setup_abort\n" ;环境变量AFL_SHM_ENV不存在,共享内存映射失败 "\n" " pushl %eax\n" ; eax = getenv(AFL_SHM_ENV) " call atoi\n" ; eax = atoi(getenv(AFL_SHM_ENV)) " addl $4, %esp\n" "\n" " pushl $0 /* shmat flags */\n" " pushl $0 /* requested addr */\n" " pushl %eax /* SHM ID */\n" " call shmat\n" ; eax = shmat(shm_id, 0, 0) " addl $12, %esp\n" "\n" " cmpl $-1, %eax\n" " je __afl_setup_abort\n" "\n" " /* Store the address of the SHM region. */\n" "\n" " movl %eax, __afl_area_ptr\n" " movl %eax, %edx\n" "\n" " popl %ecx\n" " popl %eax\n" "\n"
分析上述桩代码,其实主要作了以下几件事:
0x03 forkserver forkserver主要是为了避免频繁调用execve()引起的开销。在完成了共享内存映射后,就会进入forkserver,执行__afl_forkserver。
首先,看一下forkserver进程是如何创建的。AFL通过init_forkserver() 进行forkserver相关的初始化工作:
创建状态管道和命令管道,用于AFL和forkserver进程之间的通信:int st_pipe[2], ctl_pipe[2];
AFL通过写命令管道向forkserver发送命令,forkserver通过读命令管道接收AFL的发送的命令;forkserver通过写状态管道向AFL发送信息,AFL通过读状态管道接收forkserver发送的信息。
创建forkserver进程:forksrv_pid = fork(); 在forkserver进程中:
首先对状态管道和命令管道进行重定位:dup2(ctl_pipe[0], FORKSRV_FD) 和 dup2(st_pipe[1], FORKSRV_FD + 1)。
之后,forkserver进程执行execv(target_path, argv); forkserver调用了execv之后,会在target第一个基本块处执行插入的桩代码,调用__afl_maybe_log,然后跳到__afl_setup设置共享内存。共享内存设置完毕后,就进入了__afl_forkserver。
接下来看一下__afl_forkserver:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 "__afl_forkserver:\n" "\n" " /* Enter the fork server mode to avoid the overhead of execve() calls. */\n" "\n" " pushl %eax\n" " pushl %ecx\n" " pushl %edx\n" "\n" " /* Phone home and tell the parent that we're OK. (Note that signals with\n" " no SA_RESTART will mess it up). If this fails, assume that the fd is\n" " closed because we were execve()d from an instrumented binary, or because\n" " the parent doesn't want to use the fork server. */\n" "\n" " pushl $4 /* length */\n" " pushl $__afl_temp /* data */\n" " pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n" " call write\n" ; write(STRINGIFY((FORKSRV_FD + 1)), __afl_temp, 4) " addl $12, %esp\n" "\n" " cmpl $4, %eax\n" " jne __afl_fork_resume\n" "\n"
forkserver首先会向状态管道写端(即 FORKSRV_FD + 1)写入4字节的内容,告诉AFL“我准备好fork了 ”,而AFL进程也会通过读状态管道,判断forkserver进程是否创建成功:rlen = read(fsrv_st_fd, &status, 4)。
forkserver创建成功后,就会进入__afl_fork_wait_loop ,forkserver会阻塞,直到读取命令管道成功:read(STRINGIFY(FORKSRV_FD), __afl_tmp, 4),然后forkserver判断AFL是否发送了“fork一个子进程 “的命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 "__afl_fork_wait_loop:\n" "\n" " /* Wait for parent by reading from the pipe. Abort if read fails. */\n" "\n" " pushl $4 /* length */\n" " pushl $__afl_temp /* data */\n" " pushl $" STRINGIFY(FORKSRV_FD) " /* file desc */\n" " call read\n" ; read(STRINGIFY(FORKSRV_FD), __afl_tmp, 4) " addl $12, %esp\n" "\n" " cmpl $4, %eax\n" " jne __afl_die\n" "\n" " /* Once woken up, create a clone of our process. This is an excellent use\n" " case for syscall(__NR_clone, 0, CLONE_PARENT), but glibc boneheadedly\n" " caches getpid() results and offers no way to update the value, breaking\n" " abort(), raise(), and a bunch of other things :-( */\n" "\n"
当forkserver收到AFL创建一个子进程的命令后,就会调用fork()创建target进程:
1 2 3 4 5 " call fork\n" "\n" " cmpl $0, %eax\n" " jl __afl_die\n" " je __afl_fork_resume\n"
在target进程里面,会跳到__afl_fork_resume执行,关闭文件描述符,恢复target的正常执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 "__afl_fork_resume:\n" "\n" " /* In child process: close fds, resume execution. */\n" "\n" " pushl $" STRINGIFY(FORKSRV_FD) "\n" " call close\n" "\n" " pushl $" STRINGIFY((FORKSRV_FD + 1)) "\n" " call close\n" "\n" " addl $8, %esp\n" "\n" " popl %edx\n" " popl %ecx\n" " popl %eax\n" " jmp __afl_store\n" "\n"
在forkserver进程里面,也就是在父进程里面,会将target进程的PID写入状态管道,然后等待target进程结束。target进程结束后,forkserver会再次向AFL说“我准备好fork了 ”,并继续执行 __afl_fork_wait_loop,等待AFL发送“fork一个子进程 “的命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 " /* In parent process: write PID to pipe, then wait for child. */\n" "\n" " movl %eax, __afl_fork_pid\n" "\n" " pushl $4 /* length */\n" " pushl $__afl_fork_pid /* data */\n" " pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n" " call write\n" " addl $12, %esp\n" "\n" " pushl $0 /* no flags */\n" " pushl $__afl_temp /* status */\n" " pushl __afl_fork_pid /* PID */\n" " call waitpid\n" " addl $12, %esp\n" "\n" " cmpl $0, %eax\n" " jle __afl_die\n" "\n" " /* Relay wait status to pipe, then loop back. */\n" "\n" " pushl $4 /* length */\n" " pushl $__afl_temp /* data */\n" " pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n" " call write\n" " addl $12, %esp\n" "\n" " jmp __afl_fork_wait_loop\n"
0x04 边覆盖记录 在__alf_maybe_log 中,如果共享内存完成了映射,就会执行__afl_store,在共享内存中更新边覆盖情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 "__afl_store:\n" "\n" " /* Calculate and store hit for the code location specified in ecx. There\n" " is a double-XOR way of doing this without tainting another register,\n" " and we use it on 64-bit systems; but it's slower for 32-bit ones. */\n" "\n" #ifndef COVERAGE_ONLY " movl __afl_prev_loc, %edi\n" ;将__alf_prev_loc的值存储到寄存器edi " xorl %ecx, %edi\n" ;将“__alf_prev_loc 异或 ecx”的值存储到edi寄存器中,相当于将边ID存储到了寄存器edi中 " shrl $1, %ecx\n" ;将ecx的值右移1位,然后存储至ecx寄存器中 " movl %ecx, __afl_prev_loc\n" ;将ecx寄存器的值存储到__afl_prev_loc中 #else " movl %ecx, %edi\n" #endif /* ^!COVERAGE_ONLY */ "\n" #ifdef SKIP_COUNTS " orb $1, (%edx, %edi, 1)\n" #else " incb (%edx, %edi, 1)\n" #endif /* ^SKIP_COUNTS */ "\n"
__afl_store的作用是计算前一个基本块(pre_location)到当前基本块(cur_location)这条边的ID,然后统计其出现次数。具体地,AFL使用(pre_location >> 1) xor (cur_locatino) 的方式记录一条边;使用共享内存(存储在寄存器edx中)统计边的出现次数。在上述汇编代码中:R(MAP_SIZE)得到的值,也就是存储着为当前这个基本块分配的ID,即伪代码中的cur_location;__afl_prev_loc表示上一个基本块的ID>>1 ;incb (%edx, %edi, 1)这条指令就在共享内存(edx)中,将这条边(edi)的出现次数+1。
__afl_store之后是__afl_return:\n。
1 2 3 4 5 6 "__afl_return:\n" "\n" " addb $127, %al\n" " sahf\n" " ret\n" "\n"
关于插桩,可能会存在两个疑问:Be Sensitive and Collaborative: Analyzing Impact of Coverage Metrics in Greybox Fuzzing 对不同代码覆盖率统计方式对于fuzzing的影响进行了研究。CollAFL 提出了新的边ID计算方式,CSI-Fuzz 也设计了新的插桩方式。
0x05 总结
AFL进程创建了forkserver进程,forkserver进程根据AFL的指令创建target进程。
AFL和forkserver通过管道进行通信
AFL和target通过共享内存通信,获取目标程序代码覆盖信息。AFL通过trace_bits访问共享内存,target通过__afl_area_ptr访问共享内存
AFL使用边覆盖信息
0x06 参考文献 https://github.com/google/AFL/
http://rk700.github.io/2017/12/28/afl-internals/